Deep Learning on VOXL 2’s GPU and NPU



Table of contents
VOXL 2 aims to deliver state-of-the-art machine learning performance through both GPU and NPU acceleration on the QRB5165. This is best illustrated through voxl-tflite-server, our server which demonstrates great capacity for on-device inference of LiteRT (formerly TesnorFlow Lite) models.

Configuration
voxl-tflite-server includes a helper script, voxl-configure-tflite, which will walk you through the available default configurations depending on your platform. This script will generate a config file at /etc/modalai/voxl-tflite-server.conf that will be used on initialization.
Available Params:
skip_n_frames- how many frames to skip between processed frames. For 30Hz input frame rate, we recommend skipping 5 frame resulting in 5hz model output. For 30Hz/maximum output, set to 0.model- which model to use.input_pipe- which camera to use (tracking, hires, or stereo).delegate- optional hardware acceleration. If the selection is invalid for the current model/hardware, will quietly fall back to base cpu delegate.
VOXL 2 Additional Params:
allow_multiple- remove process handling and allow multiple instances of voxl-tflite-server to run. Enables the ability to run multiples models simultaneously.output_pipe_prefix- if allow_multiple is set, create output pipes using default names (tflite, tflite_data) with added prefix. ONLY USED IF allow_multiple is set to true.
Output
The output stream is setup as a normal camera pipe under /run/mpa/tflite. As such, it can be viewed with voxl-portal, converted to ROS with voxl_mpa_to_ros, and logged to disk with voxl-logger.
Each model will provide a different custom overlay, depending on the task it is doing. The overlays will all contain an fps counter + inference timer in the top left.
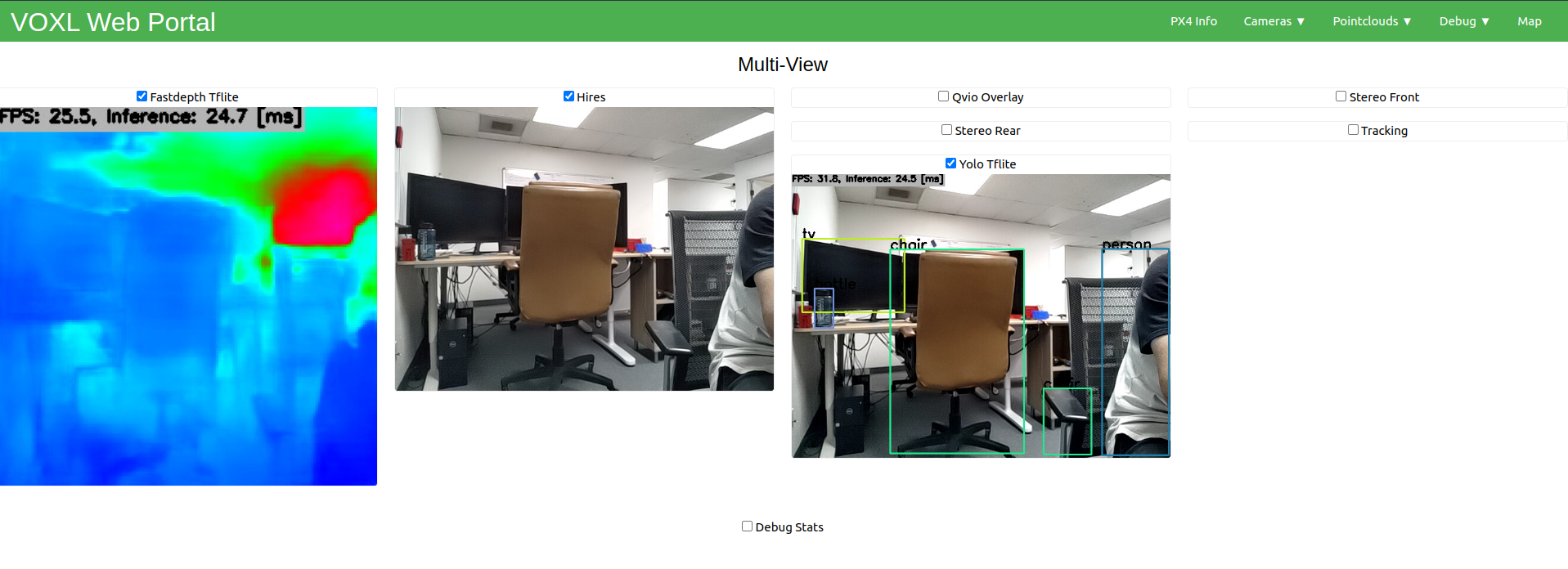
When running an object detection model, you will also see the pipe /run/mpa/tflite_data. This output pipe will provide some metadata about each object detected by the model. The format of this metadata is as follows:
// struct containing all relevant metadata to a tflite object detection
typedef struct ai_detection_t {
uint32_t magic_number;
int64_t timestamp_ns;
uint32_t class_id;
int32_t frame_id;
char class_name[BUF_LEN];
char cam[BUF_LEN];
float class_confidence;
float detection_confidence;
float x_min;
float y_min;
float x_max;
float y_max;
} __attribute__((packed)) ai_detection_t;
The tflite_data output is also compatible with voxl_mpa_to_ros, or can be subscribed to with a custom MPA client of your own.
Benchmarks
Stats were collected across 5000 inferences, using hires [640x480x3] camera as input.
| Model | Task | Avg Cpu Inference(ms) | Avg Gpu Inference(ms) | Avg NNAPI Inference(ms) | Max Frames Per Second(fps) | Input Dimensions | Source |
|---|---|---|---|---|---|---|---|
| MobileNetV2-SSDlite | Object Detection | 33.89ms | 24.68ms | 34.42ms | 34.86750349 | [1,300,300,3] | link |
| EfficientNet Lite4 | Classifier | 115.30ms | 24.74ms | 16.42ms | 48.97159647 | [1,300,300,3] | link |
| FastDepth | Monocular Depth | 37.34ms | 18.00ms | 37.32ms | 45.45454546 | [1,320,320,3] | link |
| DeepLabV3 | Segmentation | 63.03ms | 26.81ms | 61.77ms | 32.45699448 | [1,321,321,3] | link |
| Movenet SinglePose Lightning | Pose Estimation | 24.58ms | 28.49ms | 24.61ms | 34.98950315 | [1,192,192,3] | link |
| YoloV5 | Object Detection | 88.49ms | 23.37ms | 83.87ms | 36.53635367 | [1,320,320,3] | link |
| MobileNetV1-SSD | Object Detection | 19.56ms | 21.35ms | 7.72ms | 85.324232082 | [1,300,300,3] | link |
| MobileNetV1 | Classifier | 19.66ms | 6.28ms | 3.98ms | 125.313283208 | [1,224,224,3] | link |
| Model | Task | Avg Cpu Inference(ms) | Avg Gpu Inference(ms) | Max Frames Per Second(fps) | Input Dimensions | Source |
|---|---|---|---|---|---|---|
| MobileNetV2-SSDlite | Object Detection | 127.78ms | 21.82ms | 37.28560776 | [1,300,300,3] | link |
| MobileNetV1-SSD | Object Detection | 75.48ms | 64.40ms | 14.619883041 | [1,300,300,3] | link |
| MobileNetV1 | Classifier | 56.70ms | 56.85ms | 16.47446458 | [1,224,224,3] | link |
Custom Datasets
Yolov8
We have provided a guide for training Yolov8 for VOXL 2 here to support object recognition of custom images.
Custom Models
voxl-tflite-server is intended to serve as an example for how one can use libmodal-pipe to ingest images and use a trained model to perform inference. It provides a reference to enable use of common deep learning models on VOXL 2. Each model requires effort for integration and compatibility with the LiteRT (formerly Tensor Flow Lite) This is because the central logic for passing the input tensor and parsing the output tensor are specific to the model being trained and it would take a significant amount of time to build a library to to so.
Setup
Integrating your custom models on your voxl is quite easy. The voxl-tflite-server intends to serve as a modular codebase to allow you to add your own models seamlessly.
The below setps outline a process for getting your custom model loaded into voxl-tflite-server.
Convert your model to LiteRT
From Pytorch
Direct conversion of PyTorch to tensorflow is a bit messy, so it is recommended to use the ONNX format as an intermediary. Many open source models provide an ONNX format model file for deployement along with PyTorch as well. Please find more information here.
From ONNX
For conversion from the ONNX format you may use Qualcommm AI Hub and select the ‘RB5 (Proxy)’ device. onnx2tf is a great open source alternative as well which can be found here.
Post-Training Quantization
To deploy a custom model on VOXL 2, first start by validating your model on your desktop. Use Google’s Guide to learn how to develop a TensorFlow Lite model.
Once you have a model that is ready to convert to tflite format, it is necessary to do some post-training quantization. This process will enable hardware acceleration on the gpu and ensure it is compatible with the voxl-tflite-server.
A simple python script can be used for this process. Below is an example that will convert the frozen inference graph of a TensorFlow object detection model to a tflite model using our standard options (float16 quantization for gpu target):
# IF ON VOXL 1, MAKE SURE TF VERSION IS <= 2.2.3
# i.e., pip install tensorflow==2.2.3
import tensorflow as tf
# if you have a saved model and not a frozen graph, see:
# tf.compat.v1.lite.TFLiteConverter.from_saved_model()
# INPUT_ARRAYS, INPUT_SHAPES, and OUTPUT_ARRAYS may vary per model
# please check these by opening up your frozen graph/saved model in a tool like netron
converter = tf.compat.v1.lite.TFLiteConverter.from_frozen_graph(
graph_def_file = '/path/to/.pb/file/tflite_graph.pb',
input_arrays = ['normalized_input_image_tensor'],
input_shapes={'normalized_input_image_tensor': [1,300,300,3]},
output_arrays = ['TFLite_Detection_PostProcess', 'TFLite_Detection_PostProcess:1', 'TFLite_Detection_PostProcess:2', 'TFLite_Detection_PostProcess:3']
)
# IMPORTANT: FLAGS MUST BE SET BELOW #
converter.use_experimental_new_converter = True
converter.allow_custom_ops = True
converter.target_spec.supported_types = [tf.float16]
tflite_model = converter.convert()
with tf.io.gfile.GFile('model_converted.tflite', 'wb') as f:
f.write(tflite_model)
If you are using VOXL 2, the conversion process is the same but you can use the current version of the converter api and Tensorflow v2.8.0.
Note that there are various delegates available depending on your platform, but they each require different quantization types for optimal performance (i.e. when targeting the gpu, we typically use floating point models, but for the npu we use integer models).
Implementing your Model in voxl-tflite-server
To get started, you must first move your .tflite file to
/usr/bin/dnn/on your voxl. Do the same for your labels file if applicable.In the function
initialize_model_settingsin themainfile, add a conditional corresponding to your particular model in the same format as the others. Models in the voxel-file-server are indexed using two the model name and the model category. For example, the objection detection yolov8 model has the model nameYOLOV8and the model categoryOBJECT_DETECTION. The enums for these are provided inmodel_info.h.Then in the function
create_model_helperinmodel_helper.cpp, add a switch statement corresponding to your attributes and return an instantiation of your model class (more details on that in the next section).
Writing the Model class
You need to create a header and source file for your model and write the corresponding Helper class. Your class must inherit the common base class provided in model_helper.h and model_helper.cpp. Add these files to include/model_helper/ and src/model_helper/ respectively. You may go through the implementation of the other classes to get an idea of what exactly needs to be done.
Your class will have the following methods
preprocess : This method contains the pre-procesing logic for your model before it is passed for inference. There is a default implementation provided in the model_helper.cpp. It can be overriden if needed.
run_inference: This method invokes the tflite interpreter using your
.tflitefile and passes in the preprocessed input. It can be overriden if your model requires different logic.post_process: This method needs to be implemented by you according to your model’s requirements. This method is invoked by the worker method.
worker: This method performs operations external to the model which are required by other voxl functions such as passing post-processed images to their relevant pipes and timestamping frames. This method invokes the postprocess method and must also be implemented based on model functionality. You may have a look at the other worker methods to get an idea on how to write your own.
There are generic implementations provided for all the different model categories and you may use those base objects if they fit your needs. You are free to choose between them or your custom implementation, or define a new model category all together.
Upon completition of the above steps, your model is now ready to run on the voxl. To make it appear on the configuration screen, simply update the voxl-configure-tflite file.
Running Multiple Models
On VOXL 2, we expose some extra parameters to enable running multiple instances of voxl-tflite-server simultaneously. Doing so will require the following configuration file modifications:
- first set
allow_multipleto true - then, to prevent overwriting pipe names, set the
output_pipe_prefixto something unique (relative to the other instances of the tflite-server you will be running) - finally, you can start the server via a custom service file (see the base file for reference here) or via shell as normal
- before starting another instance, update the
output_pipe_prefixto prevent overwriting, and continue as before.
The board will heat up much quicker when running multiple models. Adding an external fan if not in flight can help combat the extra heat.
Demo
Source
Source code is available on Gitlab
Frequently Asked Questions (FAQ)
I want to use my Python script to pre/post-process inputs/outputs to the model, how can I do this? The inputs and outputs for the model are both done using libmodal-pipe which only supports C/C++ and so there isn’t a way to directly interface with Python. However, it’s possible to use libmodal-pipe to create a very simple wrapper which consumes from a pipe, runs a Python executable, and then passes information along to another pipe. In the libmodal-pipe repo check out the examples dir for an example of setting up a basic pipe interface on VOXL.
Why is my model is predicting less accurately when deployed on VOXL? If you’re passing it to voxl-tflite-server, some preprocessing and postprocessing is done on the image tensors which may differ from what you’ve done locally. Quantization can also reduce performance over a non-quantized model.